This page serves as a wishlist for FireCloud features needed by the Broad GDAC to match the productivity of FireHose. The minutes from the meeting where this was discussed are given in this Google Doc. At the end of those minutes is an explanation of how GDAC workflows operate, and how we use job avoidance and optionality to manage the execution of workflows on a heterogenous and dynamically growing dataset.
...
- More sophisticated complex expressions
GDAC data is notoriously messy, and certain algorithms are generalized across a variety of data subtypes. For this reason, task configurations in FireHose had MVEL expressions that would, among other things, allow "choosing" between two possible inputs, and FireHose would figure out how to map the correct inputs to the workflow language. In FireCloud, we only have simple expressions, either literals, attributes, or attributes of members in a set. (like this: "Value", "this.value", "this.samples.value"). Having only these features necessitates ugly (and hard to maintain) hacks, such as spinning up a VM to choose between input files as a task, or adding extra optional inputs to WDL and parsing as the first step in a task. - Built-in attribute/expression evaluator
(I think Chet entered a story/ticket for this) To see the parameters a given workflow or config in any space would be given if launched with a given entity, but without launching it: This was described in 2012 for Firehose CGA 2012_09_28 presentation p. 41-46: fiss task_eval <space> <iset> <task_name>
...
"Map" data type
A common use case in FireHose is to select input files from samples in a sample set, and pass these files to an analysis via a two-column tsv file that maps sample ids to the data files. An analagous method exists in FireCloud, allowing you to accept as input an array of sample ids and an array of the data files. The problem arises when the data is sparse – the two arrays are no longer parallel, and the mapping is broken. From a task-authors perspective, this could be solved if there was a Map data type in WDL. In Firecloud, you could pass the input as "this.samples.name->this.samples.data", and not require any sort of Null sentinel value in the bucket.
Compostability/ Imports
Different workflows will often share common tasks, such as a preprocessor or a report generator. Since WDLs are not composeable, each workflow must independently maintain a copy of the task. A temporary solution used by gdac-firecloud is to use a script to sync task definitions within the repository, but this has limitations. First, it only works with tasks defined in the repository. It also requires manual intervention by the workflow developer, via 'make sync'. Import statements are currently part of the WDL spec, but are not implemented in FireCloud or any of the development tools (i.e. Cromwell, wdltool, etc.).
Versioning
How are singleton tasks configs versioned? How does that relate to composite versioning and job avoidance? e.g. AFAIK a composite task is built by literal inclusion of its component singleton tasks. But where is the version of each singleton task "stored" in the composite WDL? And how are these versions checked so that single tasks can be avoided properly? Moreover, if I update singleton task T and want to update all of the composite tasks C1, C2 ... CN of which it's a member, how do I discern C1...CN and how can I automatically update them when T is updated?Feedback: part of this is already handled, because when a singleton task (or step) in a workflow is updated that update is manifest as a new docker container, which yields a new hash;
...
- Long google bucket paths are unreadable, abbreviate to file basenames since in most cases, the directory structure is irrelevant, especially from the Data Model's perspective.
- List of stories entered by Chet from Mike's UI diagrams (I will share during the meeting)
- Sticky preferences: which namespace I last worked in, or which namespace I most prefer to work in, ditto for workspace(s), what is my favorite "results per page" setting
- Edit/Update WDL - Require to upload through the command line for even minor changes. Update without losing the entire configuration.
- Annotation validity - Inability to determine valid annotations when configuring a wdl
- Table search filters should be stateful – For example, in the methods repository, I can search for a particular method, and I will see all available versions. If I want to redact or update several at once, I have to re enter my search every time after making my edits. On return to the table, the UI should remember my last search.
API
- Accurate Documentation
The current api page is intended to list all available orchestration (read user-available) api calls. But this page is either incomplete, or does not accurately represent the available API calls. On a couple occasions, Alex has directed me to an API endpoint that is not listed on this page, but is listed on the page for the service (Rawls, Agora, etc.) at https://swagger.dsde-dev.broadinstitute.org/ . Some of these APIs are publicly accessible as pass-throughs, but the distinction has not been made clear. - Get latest snapshot of Method or Config
Some endpoints require a snapshot_id (e.g. https://swagger.dsde-dev.broadinstitute.org/#!/Method_Repository/getMethodRepositoryConfiguration), but there isn't an easy way to figure out what the latest snapshot id is without retrieving all snapshot_ids and performing a max check. For these endpoints, there should be a 'latest' option, or the snapshot_id should be optional, and the latest version is retrieved.
...
| Panel | ||
|---|---|---|
| ||
Some tasks in the GDAC Firehose domain have both required and optional inputs, such as the http://gdac.broadinstitute.org/Analyses-DAG.html Any such task with optional inputs will not be launched by Firehose until 2 constraints are met:
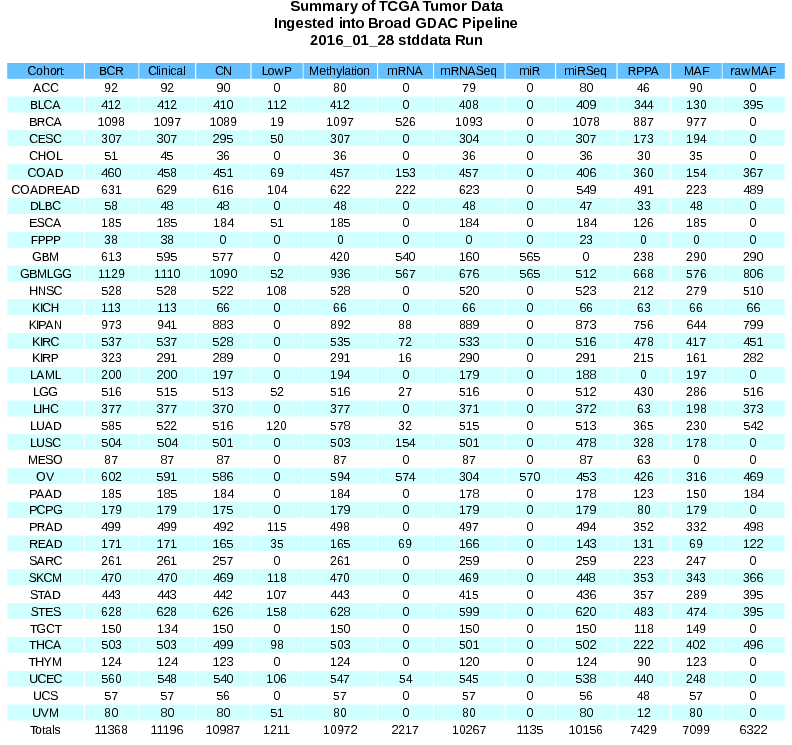
To satisfy constraint (2) Firehose looks recursively backward on the DAG, and delays launching a downstream task until it determines that there are zero remaining optional upstream tasks that can possibly be launched or executed to successful completion. As described below, this feature has been very helpful when running the GDAC analysis workflow, and its absence from FireCloud—which requires that only constraint (1) be satisfied before launching a task— implies that the current GDAC Analyses workflow cannot be ported “as is” from Firehose to FireCloud; to run on FireCloud this workflow and/or tasks within it will need to be modified, perhaps substantially. To understand how constraint (2) arose it’s helpful to examine (a) the structure of the data upon which the GDAC workflow operates, and (b) how that data is generally made available over time. We use TCGA to make things concrete, but a similar pattern holds for the operational phase of many data-intensive scientific projects. First, the workflow is run for 38 independent disease cohorts (sets of patient samples); and each sample within a cohort may be characterized in as many as 10 different ways (yielding up to 10 distinct kinds of data, or data types, for each patient sample). The table at http://gdac.broadinstitute.org/runs/stddata__latest/ingested_data.png shows both the disease cohorts (rows) and data types (columns) in the corpus of TCGA data. Notice the heterogeneity in this data, in both the sizes of disease cohorts as well as the data types each of them offer. What the table doesn’t show, because the TCGA is done collecting data, is that at any given moment during the TCGA project many of the cells in this table were empty; so that, in general, when executing our analysis workflow on any given cohort some of the input arcs to the Note that when job avoidance is possible in FireCloud we would in principle be able to use brute force to execute the complete GDAC workflow, even without optionality. This approach would entail running the workflow over and over, in as many passes as needed until everything that can be run has been run. For example: suppose in Pass1 perhaps 60% of the workflow might execute “as is,” with downstream tasks launched as soon as their required inputs are available (no waiting for optional inputs that are not yet available); in Pass2 at most 60% of the workflow might job avoid, and perhaps more upstream tasks might complete for the first time, making a larger set of optional inputs available to downstream tasks, so that perhaps 80% of the entire workflow might complete; finally, in Pass3 up to 80% of the workfow might be avoided, and perhaps all optional upstream artifacts that could be generated were in fact generated, allowing the remaining 20% of the downstream workflow to complete. As stated in our grant review, the NIH has expressed considerable interest in the use of FireCloud as a Global Platform for Collaborative Extreme-Scale Analysis, (as well as in its potential for solving forevermore the reproducibility problem for computational analyses). So we expect that workflows of the type we run now to become much more than "just for the Broad GDAC," but rather something that is directly utilized by numerous analysis working groups across the cancer research community. In addition, we are in the final stages of receiving funding for a GDAC-like center for proteomics (within the CPTAC), and are also using Firehose/FireCloud for GDAC-style analyses in the GTEX consortium. Altogether this means that our GDAC-style workflows have the potential for global impact across multiple scientific communities, going far beyond just one group at one institute, and effectively helping realize the original vision of the GDR and Prometheus at the Broad. |
{kind=link}